bupaR Docs | Create Logs
![]()
Creating logs
Transforming your raw data into an event log object is one of the most challenging tasks in process analysis. On this page, we cover all the possible situations and challenges that you can encounter.
We start with some important terminology:
- Case: The subject of your process, e.g. a customer, an order, a patient.
- Activity: A step in your process, e.g. receive order, sent payment, perform MRI SCAN, etc.
- Activity instance: The execution of a specific step for a specific case.
- Event: A registration connected to an activity instance, characterized by a single timestamp. E.g. the start of Perform MRI SCAN for Patient X.
- Resource: A person or machine that is related to the execution of (part of) an activity instance. E.g. the radiologist in charge of our MRI SCAN.
- Lifecycle status: An indication of the status of an activity instance connect to an event. Typical values are start, complete. Other possible values are schedule, suspend, resume, etc.
- Trace: A sequence of activities. The activity instances that belong to a case will result to a specific trace when ordered by the time each instance occurred.
Logs: eventlog vs activitylog
bupaR supports two different kinds of log formats, both
of which are an extension on R data.frame:
eventlog: Event logs are created fromdata.framein which each row represents a single event. This means that it has a single timestamp.activitylog: Activity logs are created fromdata.framein which each row represents a single activity instances. This means it can has multiple timestamps, stored in different columns.
The data model below shows the difference between these two levels of observations, i.e. activity instances vs events.
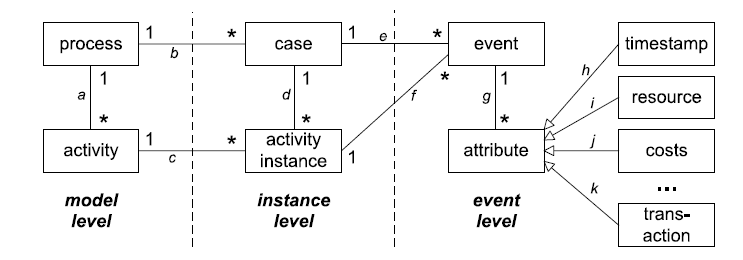
The example below shows an excerpt of an event log containing 6 events. It can be seen that each event is linked to a single timestamp. As there can be more events within a single activity instance, each event also needs to be linked to a lifecycle status (here the registration_type). Furthermore, an activity instance identifier (handling_id) is needed to indicated which events belong to the same activity instances.
| handling | patient | employee | handling_id | registration_type | time |
|---|---|---|---|---|---|
| Registration | 207 | r1 | 207 | start | 2017-07-20 22:31:31 |
| Triage and Assessment | 207 | r2 | 707 | start | 2017-07-21 01:29:30 |
| Registration | 207 | r1 | 207 | complete | 2017-07-21 01:29:30 |
| Triage and Assessment | 207 | r2 | 707 | complete | 2017-07-21 16:45:28 |
| Blood test | 207 | r3 | 1101 | start | 2017-07-25 08:14:46 |
| Blood test | 207 | r3 | 1101 | complete | 2017-07-25 15:23:36 |

The table below show the same data as above, but now using the
activitylog format. It can be seen that there are now just
3 rows instead of 6, but each row as 2 timestamps, representing 2
events. The lifecycle status represented by those timestamps is now the
column names of those variables.
| handling | patient | employee | handling_id | complete | start |
|---|---|---|---|---|---|
| Registration | 207 | r1 | 207 | 2017-07-21 01:29:30 | 2017-07-20 22:31:31 |
| Triage and Assessment | 207 | r2 | 707 | 2017-07-21 16:45:28 | 2017-07-21 01:29:30 |
| Blood test | 207 | r3 | 1101 | 2017-07-25 15:23:36 | 2017-07-25 08:14:46 |
As these examples show, both formats can often be used for representing the same process data. However, there are some important differences between them:
- the
eventlogformat has much more flexibility in terms of lifecycle. There is no limit to the number of events that can occur in a single activity instance. If your data contains lifecycle statuses such as suspend, resume or reassign, they can be recorded multiple times within a single activity instance. In theactivitylogformat, as each lifecycle gets is own column, it isn’t possible to have two events of the same lifecycle status in a single activity instance. - the level of observation in an
eventlogis an event. As a result, attribute values can be stored at the event level. In anactivitylog, the level of observation is an activity instance. This means that all additional attributes that you have about your process should be at this higher level. For example, an activity instance can only be connected to a single resource in theactivitylogformat, whereas in aneventlogdifferent events within the same activity instance can have different resources, of different values for any other attribute. - because of the limited flexibility, an
activitylogis easier to make, and typically closer to the format that your data is already in (see further below on how to constructlogobjects). As a result of this, there are many situations in which the analysis of anactivitylogwill be much faster compared toeventlog, where a lot of additional complexity needs to be taken into account.
The right log for the job
Functionalities in bupaR core packages support both formats. 1 As such, the goal of your analysis does not impact the decision. Only the complexity of your data is important to make this decision. The precise format your raw data is in will further define the preparatory steps that are needed. We can distinguish between 3 typical scenarios. The flowchart below helps you on your way.

An activitylog is the best option when each row in your
data is an activity instance, or when events belonging to the same
activity instance have equal attribute values (e.g. all events are
executed by the same resource). When these two criteria do not hold, you
can create an eventlog object.
Scenario 1
If each row in your data.frame is already an activity
instance, the activitylog format is the best way to go.
Consider the data sample below.
| patient | handling | activity_started | activity_ended |
|---|---|---|---|
| 155 | Check-out | 2017-06-05 15:58:53 | 2017-06-05 17:22:16 |
| 155 | Discuss Results | 2017-06-05 14:03:19 | 2017-06-05 15:58:53 |
| 155 | Registration | 2017-06-03 10:05:28 | 2017-06-03 14:19:00 |
| 155 | Triage and Assessment | 2017-06-04 06:27:00 | 2017-06-04 14:23:26 |
| 155 | X-Ray | 2017-06-05 00:12:24 | 2017-06-05 04:39:38 |
As each row contains multiple timestamps, i.e. activity_started and
activity_ended, it is clear that each row represents an activity
instance. Turning this dataset in an activitylog requires
the following steps:
- Timestamp variables should be named in correspondence with the standard Transactional lifecycle.
- Timestamp variables should be of type
DateorPOSIXct. - Use the
activitylogconstructor function.
data %>%
# rename timestamp variables appropriately
dplyr::rename(start = activity_started,
complete = activity_ended) %>%
# convert timestamps to
convert_timestamps(columns = c("start", "complete"), format = ymd_hms) %>%
activitylog(case_id = "patient",
activity_id = "handling",
timestamps = c("start", "complete"))## # Log of 10 events consisting of:
## 1 trace
## 1 case
## 5 instances of 5 activities
## 0 resources
## Events occurred from 2017-06-03 10:05:28 until 2017-06-05 17:22:16
##
## # Variables were mapped as follows:
## Case identifier: patient
## Activity identifier: handling
## Resource identifier: employee
## Timestamps: start, complete
##
## # A tibble: 5 × 5
## patient handling start complete .order
## <chr> <fct> <dttm> <dttm> <int>
## 1 155 Check-out 2017-06-05 15:58:53 2017-06-05 17:22:16 1
## 2 155 Discuss Results 2017-06-05 14:03:19 2017-06-05 15:58:53 2
## 3 155 Registration 2017-06-03 10:05:28 2017-06-03 14:19:00 3
## 4 155 Triage and Assessment 2017-06-04 06:27:00 2017-06-04 14:23:26 4
## 5 155 X-Ray 2017-06-05 00:12:24 2017-06-05 04:39:38 5Note that in case a resource identifier is available, this
information can be added in the activitylog call.
Scenario 2
If each row in your data.frame is an event, but all
events that belong to the same activity instance share the same
attribute values, the activitylog format is again the best
way to go. Consider the data sample below.
| patient | handling | employee | handling_id | registration_type | time |
|---|---|---|---|---|---|
| 173 | Registration | r1 | 173 | started | 2017-06-18 20:54:33 |
| 173 | Registration | r1 | 173 | completed | 2017-06-18 23:45:36 |
| 173 | Triage and Assessment | r2 | 673 | started | 2017-06-19 15:40:32 |
| 173 | Triage and Assessment | r2 | 673 | completed | 2017-06-20 04:53:58 |
| 173 | Blood test | r3 | 1083 | started | 2017-06-21 08:02:20 |
| 173 | Blood test | r3 | 1083 | completed | 2017-06-21 12:46:08 |
| 173 | MRI SCAN | r4 | 1320 | started | 2017-06-21 18:03:06 |
| 173 | MRI SCAN | r4 | 1320 | completed | 2017-06-21 23:36:44 |
| 173 | Discuss Results | r6 | 1907 | started | 2017-06-22 08:40:55 |
| 173 | Discuss Results | r6 | 1907 | completed | 2017-06-22 12:20:12 |
| 173 | Check-out | r7 | 2402 | started | 2017-06-25 17:05:13 |
| 173 | Check-out | r7 | 2402 | completed | 2017-06-25 19:29:14 |
The resource identifier (employee) has been added as an additional
attribute. Note that though each row is an event, they can be grouped
into activity instances using the handling_id column, which we will call
the activity instance id. Using the latter, we can see that the resource
attribute is the same within each activity instance, which allows us to
create an activitylog. The steps to do so are the
following.
- Lifecycle variable should be named in correspondence with the standard Transactional lifecycle.
- Timestamp variable should be of type
DateorPOSIXct. - Use the
eventlogconstructor function. - Convert to
activitylogusingto_activitylogfor reduced memory usage and improved performance.
data %>%
# recode lifecycle variable appropriately
dplyr::mutate(registration_type = forcats::fct_recode(registration_type,
"start" = "started",
"complete" = "completed")) %>%
convert_timestamps(columns = "time", format = ymd_hms) %>%
eventlog(case_id = "patient",
activity_id = "handling",
activity_instance_id = "handling_id",
lifecycle_id = "registration_type",
timestamp = "time",
resource_id = "employee") %>%
to_activitylog() -> tmp_actNote that the resource identifier is optional, and can be left out of
the eventlog call if such an attribute does not exist in
your data. If the activity instance id does not exist, some heuristics
are available to generate it: Missing activity instance
id.
Scenario 3
If each row is an event, and events of the same activity instance
have differing attribute values, the flexibility of
eventlog objects is required. Consider the data sample
below.
| patient | handling | employee | handling_id | registration_type | time |
|---|---|---|---|---|---|
| 101 | Registration | r6 | 101 | started | 2017-04-16 06:38:58 |
| 101 | Registration | r6 | 101 | completed | 2017-04-16 09:12:01 |
| 101 | Triage and Assessment | r1 | 601 | started | 2017-04-16 22:46:00 |
| 101 | Triage and Assessment | r2 | 601 | completed | 2017-04-17 10:17:27 |
| 101 | X-Ray | r7 | 1529 | started | 2017-04-18 01:05:58 |
| 101 | X-Ray | r2 | 1529 | completed | 2017-04-18 05:22:16 |
| 101 | Discuss Results | r1 | 1835 | started | 2017-04-22 08:15:23 |
| 101 | Discuss Results | r5 | 1835 | completed | 2017-04-22 11:14:53 |
| 101 | Check-out | r5 | 2330 | started | 2017-04-23 00:16:15 |
| 101 | Check-out | r7 | 2330 | completed | 2017-04-23 02:55:23 |
In this example, different resources (employees) sometimes perform
the start and complete event of the same activity instance. Therefore,
we resort to the eventlog format which has no problems
storing this. The steps to take are the following:
- Lifecycle variable should be named in correspondence with the standard Transactional lifecycle.
- Timestamp variable should be of type
DateorPOSIXct. - Use the
eventlogconstructor function.
data %>%
# recode lifecycle variable appropriately
dplyr::mutate(registration_type = forcats::fct_recode(registration_type,
"start" = "started",
"complete" = "completed")) %>%
convert_timestamps(columns = "time", format = ymd_hms) %>%
eventlog(case_id = "patient",
activity_id = "handling",
activity_instance_id = "handling_id",
lifecycle_id = "registration_type",
timestamp = "time",
resource_id = "employee") ## Warning in validate_eventlog(eventlog): The following activity instances are
## connected to more than one resource: 1529,1835,2330,601## # Log of 10 events consisting of:
## 1 trace
## 1 case
## 5 instances of 5 activities
## 5 resources
## Events occurred from 2017-04-16 06:38:58 until 2017-04-23 02:55:23
##
## # Variables were mapped as follows:
## Case identifier: patient
## Activity identifier: handling
## Resource identifier: employee
## Activity instance identifier: handling_id
## Timestamp: time
## Lifecycle transition: registration_type
##
## # A tibble: 10 × 7
## patient handling employee handling_id registration_type time
## <chr> <fct> <fct> <chr> <fct> <dttm>
## 1 101 Registrat… r6 101 start 2017-04-16 06:38:58
## 2 101 Registrat… r6 101 complete 2017-04-16 09:12:01
## 3 101 Triage an… r1 601 start 2017-04-16 22:46:00
## 4 101 Triage an… r2 601 complete 2017-04-17 10:17:27
## 5 101 X-Ray r7 1529 start 2017-04-18 01:05:58
## 6 101 X-Ray r2 1529 complete 2017-04-18 05:22:16
## 7 101 Discuss R… r1 1835 start 2017-04-22 08:15:23
## 8 101 Discuss R… r5 1835 complete 2017-04-22 11:14:53
## 9 101 Check-out r5 2330 start 2017-04-23 00:16:15
## 10 101 Check-out r7 2330 complete 2017-04-23 02:55:23
## # ℹ 1 more variable: .order <int>Note that we need an eventlog irrespective of which
attribute values are differing, i.e. it can be resources, but also any
additional variables you have in your data set. For the special case of
resource values, it might be that a different resource executing events
in the same activity instance is a data quality issue. If so, some
functions can help you to identify this issue: Inconsistent Resources.
Again, if the activity instance id does not exist, some heuristics are available to generate it: Missing activity instance id.
Typical problems
Missing activity instance id
In order to be able to correlate events which belong to the same activity instance, an activity instance identifier is required. For example, in the data shown below, it is possible that a patient has gone through different surgeries, each with their own start- and complete event. The activity instance identifier will then allow to distinguish which events belong together and which do not. It is important to note that this instance identifier should be unique, also among different cases and activities.
| patient | activity | timestamp | status | activity_instance |
|---|---|---|---|---|
| John Doe | check-in | 2017-05-10 08:33:26 | complete | 1 |
| John Doe | surgery | 2017-05-10 08:53:16 | start | 2 |
| John Doe | surgery | 2017-05-10 09:25:19 | complete | 2 |
| John Doe | treatment | 2017-05-10 10:01:25 | start | 3 |
| John Doe | treatment | 2017-05-10 10:35:18 | complete | 3 |
| John Doe | surgery | 2017-05-10 10:41:35 | start | 4 |
| John Doe | surgery | 2017-05-10 11:05:56 | complete | 4 |
| John Doe | check-out | 2017-05-11 14:52:36 | complete | 5 |
If the activity instance identifier is not available you can use the
assign_instance_id() function, which uses an heuristic to
create the missing identifier. Alternatively, you can try to create the
identifier on your own using dplyr::mutate() and other
manipulation functions.
Large Datasets and Validation
By default, bupaR validates certain properties of the
activity instances that is supplied when creating an event log:
- a single activity instance identifier must not be connected to multiple cases,
- a single activity instance identifier must not be connected to multiple activity labels,
However, these checks are not efficient and may lead to considerable
performance issues for large data frames. It is possible to deactivate
the validation in case you already know that your data fulfills all the
requirements, using the argument validate = FALSE when
creating the eventlog. Note that when the activity instance
id was created with the assign_instance_id() function, you
can assume the above properties hold.
Inconsistent Resources
Each event can contain the notion of a resource. It can be so that
different events belonging to the same activity instance are executed by
different resources, as in the eventlog below.
| patient | handling | employee | handling_id | registration_type | time | .order |
|---|---|---|---|---|---|---|
| 64 | Registration | r6 | 64 | start | 2017-03-09 14:27:30 | 1 |
| 64 | Registration | r3 | 64 | complete | 2017-03-09 15:34:48 | 2 |
| 64 | Triage and Assessment | r1 | 564 | start | 2017-03-10 05:23:06 | 3 |
| 64 | Triage and Assessment | r1 | 564 | complete | 2017-03-10 18:10:32 | 4 |
| 64 | Blood test | r6 | 1030 | start | 2017-03-11 19:31:13 | 5 |
| 64 | Blood test | r7 | 1030 | complete | 2017-03-12 02:44:53 | 6 |
| 64 | MRI SCAN | r2 | 1267 | start | 2017-03-12 10:04:03 | 7 |
| 64 | MRI SCAN | r4 | 1267 | complete | 2017-03-12 14:40:37 | 8 |
| 64 | Discuss Results | r4 | 1798 | start | 2017-03-12 22:27:56 | 9 |
| 64 | Discuss Results | r2 | 1798 | complete | 2017-03-13 00:45:14 | 10 |
| 64 | Check-out | r3 | 2293 | start | 2017-03-14 18:45:54 | 11 |
| 64 | Check-out | r7 | 2293 | complete | 2017-03-14 20:03:19 | 12 |
If you have a large dataset, and want to have an overview of the
activity instances that have more than one resource connected to them,
you can use the detect_resource_inconsistences()
function.
## # A tibble: 5 × 5
## patient handling handling_id complete start
## <chr> <fct> <chr> <chr> <chr>
## 1 64 Blood test 1030 r7 r6
## 2 64 Check-out 2293 r7 r3
## 3 64 Discuss Results 1798 r2 r4
## 4 64 MRI SCAN 1267 r4 r2
## 5 64 Registration 64 r3 r6If you want to remove these inconsistencies, a quick fix is to merge
the resource labels together with
fix_resource_inconsistencies(). Note that this is not
needed for eventlog, but it is for
activitylog. While the creation of the
eventlog will emit a warning when resource inconsistencies
exist, this should mostly be seen as a data quality warning. That said,
there might be analysis related to the counting of resources where such
inconsistencies might lead to odd results.
## *** OUTPUT ***## A total of 5 activity executions in the event log are classified as inconsistencies.## They are spread over the following cases and activities:## # A tibble: 5 × 5
## patient handling handling_id complete start
## <chr> <fct> <chr> <chr> <chr>
## 1 64 Blood test 1030 r7 r6
## 2 64 Check-out 2293 r7 r3
## 3 64 Discuss Results 1798 r2 r4
## 4 64 MRI SCAN 1267 r4 r2
## 5 64 Registration 64 r3 r6## Inconsistencies solved succesfully.## # Log of 12 events consisting of:
## 1 trace
## 1 case
## 6 instances of 6 activities
## 6 resources
## Events occurred from 2017-03-09 14:27:30 until 2017-03-14 20:03:19
##
## # Variables were mapped as follows:
## Case identifier: patient
## Activity identifier: handling
## Resource identifier: employee
## Activity instance identifier: handling_id
## Timestamp: time
## Lifecycle transition: registration_type
##
## # A tibble: 12 × 7
## patient handling employee handling_id registration_type time
## <chr> <fct> <chr> <chr> <fct> <dttm>
## 1 64 Registrat… r3 - r6 64 start 2017-03-09 14:27:30
## 2 64 Registrat… r3 - r6 64 complete 2017-03-09 15:34:48
## 3 64 Triage an… r1 564 start 2017-03-10 05:23:06
## 4 64 Triage an… r1 564 complete 2017-03-10 18:10:32
## 5 64 Blood test r7 - r6 1030 start 2017-03-11 19:31:13
## 6 64 Blood test r7 - r6 1030 complete 2017-03-12 02:44:53
## 7 64 MRI SCAN r4 - r2 1267 start 2017-03-12 10:04:03
## 8 64 MRI SCAN r4 - r2 1267 complete 2017-03-12 14:40:37
## 9 64 Discuss R… r2 - r4 1798 start 2017-03-12 22:27:56
## 10 64 Discuss R… r2 - r4 1798 complete 2017-03-13 00:45:14
## 11 64 Check-out r7 - r3 2293 start 2017-03-14 18:45:54
## 12 64 Check-out r7 - r3 2293 complete 2017-03-14 20:03:19
## # ℹ 1 more variable: .order <int>Read more:
Currently both
eventlogandactivitylogare supported by the packagesbupaR,edeaRandprocessmapR. Thedaqapopackage only supportsactivitylog, while all other packages only supporteventlog. While the goal is to extend support for both to all packages, you can in the meanwhile always convert the format of your log using the functionsto_eventlog()andto_activitylog().↩︎
Copyright © 2025 bupaR - Hasselt University